
目次
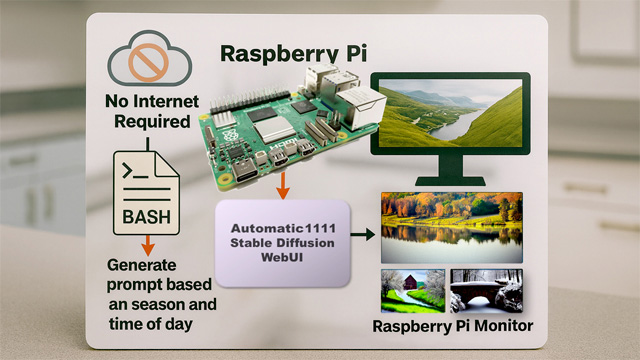
Bashスクリプトで画像生成
本稿では、Bashスクリプトで画像生成AI用のプロンプトを作成してみます。
一般的にはPythonを各種AIエンジンの制御に用います。PCや周辺機器、関連ソフトウェアとの連携に不可欠なライブラリが豊富だからです。
そういったことが得意な言語が、もう一つあります。それはBashスクリプトです。しかも、普段のコマンド操作と同じ操作で、応用できます。

生成した画像の一例
まずは、Raspberry Pi で生成した画像の一例を紹介します。
下図は Stable Diffusion の基本モデル SD1.5 による生成例です。画像1枚の解像度は512×256です。1枚につき約6分の生成時間を要しました。基本モデルなので見劣りします。とはいえ、フォトフレームに表示する風景画であれば、利用可能な範囲でしょう。

また、学習を追加したモデルに変更すると、同じ生成条件であっても、より自然な画像を生成することも可能です。

とくに人物については、モデルの利用で実写と見間違うような自然な画像を生成することができます。

画像生成実験システムの構成
本例では Raspberry Pi で画像生成を行います。クラウドを使用しないので、画像生成時のインターネット接続が不要です。フォトフレームとして単体で動かせるほか、ローカル環境でシステムを構築することができます。ただし、システムのインストールにはインターネットが必要です。
必要な機材
Raspberry Pi 4 以上で動作します。ただし、生成には 5GB ~ 9GB のメモリーが必要です。このため、RAM 8GB 以下のモデルの場合はメモリの節約が必要です(後述)。

マイクロSDカードは、ソフトウェアのインストール用に8.8GB、スワップ領域8GB、モデル追加1件につき5GBを要します。最低でも32GB以上を用意してください。スワップ時の摩耗を考慮し、高耐久(ドライブレコーダー用)が良いでしょう。
- Raspberry Pi 5 model B(RAM 8GB か 16GB を推奨)
- マイクロSDカード 32GB以上(高耐久品)
- 周辺機器(ACアダプタ、モニタ、キーボード、LAN環境など)

メンディングテープを貼っておくとカードを取り出しやすい
Stable Diffusionのインストール方法

本稿では、AUTOMATIC1111 のStable Diffusion web UI を使用します。Stable Diffusion はテキストから画像を生成するソフトウェアです。AUTOMATIC1111 は、Stable Diffusion に GUI や拡張性を追加しすることで、Stable Diffusion を一般のユーザーに広めました。
インストールは、ほぼ自動です。ただし、Pythonのバージョンや、メモリの制限、Raspberry Piが NVIDIA の GPU を搭載していない点に対応する必要があります。
それらの対応を含め、インストール手順を説明します。
Python3.11をインストールする

Python のバージョンは 3.11 を使用します。筆者が知る限り、最も手軽な方法は Raspberry Pi OS Bookworm の 2025/11/24版を使用することです。
Bookworm 2025-11-24 Lite版:https://downloads.raspberrypi.com/raspios_oldstable_lite_arm64/images/raspios_oldstable_lite_arm64-2025-11-24
Bookworm 2025-11-24 デスクトップ版:
https://downloads.raspberrypi.com/raspios_oldstable_arm64/images/raspios_oldstable_arm64-2025-11-24
Lite版にはデスクトップ環境が含まれません。起動後、CLI(コマンド・ライン・インターフェース)で操作します。この場合であっても、別のPCから Web UI を表示できます。
RAM 16GB モデルであればデスクトップ版で動作します。しかし、RAM 8GB モデルの場合は、生成時間が長くなることがあるので、CLIに抵抗が無ければLite版を使ってください。RAM 4GB モデルの場合は、Lite版が必須です。
末尾が「img.xz」のファイルをダウンロード後、Raspberry Pi Imager を使って、そのファイルをマイクロSDカード(32GB以上)に書き込み、作成したマイクロSDカードを Raspberry Pi 5 model B に差し込んでください。
ソフトウェアのインストール(1)

複雑なインストールは AUTOMATIC1111 が自動実行してくれます。とはいえ、AUTOMATIC1111 を始動するためのインストールが必要です。下記を実行してください。
$ sudo apt update
$ sudo apt install wget git python3-pip libgl1
$ cd
$ git clone http://github.com/AUTOMATIC1111/stable-diffusion-webui次に、Stable Diffusionの起動オプションを設定します。設定ファイルは Bashスクリプトです。下記のファイルをエディタで開き、環境変数 COMMANDLINE_ARGS を定義してください。
Stable Diffusionの起動設定ファイル:
~/stable-diffusion-webui/webui-user.sh
export COMMANDLINE_ARGS="--skip-torch-cuda-test --no-half --listen --api"Raspberry Pi で使用する可能性のある主なオプションを下表に示します。必要に応じて、上記のダブルクォート内に追加してください。
| ―skip-torch-cuda-test | GPUのテストを省略 (CPU処理なので必須) |
| ―no-half | FP16演算を使用しない (ARM CPUで必須) |
| ―listen | LANからWeb UIへのアクセス許可 |
| ―api | 本稿で利用するAPIの有効化 |
| ―nowebui | Web UIの無効化(RAM節約) |
| ―lowram | RAM消費を抑えるオプション (8GB以下のモデルに必要) |
| ―opt-sub-quad-attention | RAM消費を抑えつつ速度改善 |
メモリー(RAM)不足対策

Raspberry Pi の RAM容量が16GBの場合は、次節にスキップしてください。
RAM容量が 4GB や 8GB の場合は、メモリ不足対策が必要です。RAM 8GB モデルの場合は、以下のオプション設定、RAM圧縮、SDカードへのスワップ機能を設定してください。RAM 4GB モデルについては、本稿の末尾を参照してください。
- オプション設定
設定 = webui-user.sh のCOMMANDLINE_ARGSにオプション(―lowram、―opt-sub-quad-attention)を追加 - RAM圧縮
インストール = sudo apt install zram-tools
設定 = /etc/default/zramswap に ALGO=lz4、PERCENT=75 - RAMスワップ機能
設定 = /etc/dphys-swapfile に CONF_SWAPSIZE=4096、 /etc/sysctl.conf に vm.swappiness=10 を設定後、再起動
vm.swappinessが低すぎると、Out of Memoryが発生することがあります。高すぎると、生成速度が低下することがあります。生成する画像に応じて10~60までの間で調整してください。
ソフトウェアのインストール(2)

ここからは、AUTOMATIC1111 による自動インストールです。環境にもよりますが、全てのインストールを行うのに数時間を要します(Raspberry Pi 5 16GB 使用時)。
下記のBashスクリプトを実行してください。
$ cd ~/stable-diffusion-webui
$ ./webui.shwebui.shは、設定ファイルの webui-user.sh を実行後、Pythonの仮想環境を生成し、仮想環境上で launch.py を実行します。
その後、 launch.py は、必要なソフトウェアのダウンロードとインストールを自動的に行います。なお、最も時間がかかるのは、約5GBの標準モデルSD 1.5「v1-5-pruned-emaonly.safetensors」のダウンロードです。

ダウンロードが終わると、下記のメッセージが表示されます。ここで、httpの末尾のポート番号7860を確認してください。7861等になることもあります。
Running on local URL: http://0.0.0.0:7860インターネット・ブラウザで「http://(IPアドレス):7860/」にアクセスすると、下図のような画面が表示され、Stable Diffusion web UI が利用できるようになります。Lite版OSの場合は、別のPCからアクセスしてください。
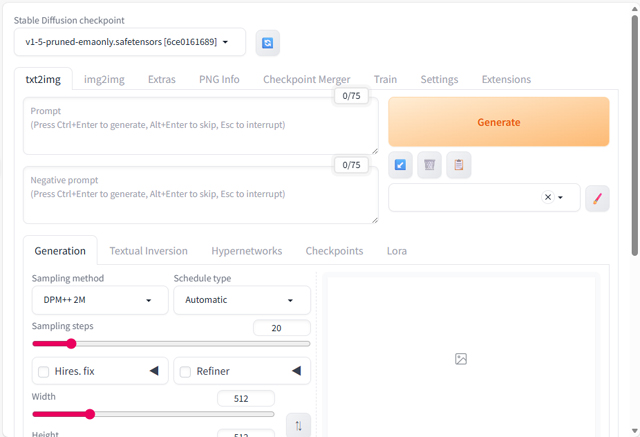
「Prompt」欄にプロンプトを入力し、[Generate]ボタンで画像生成を実行できます。

終了するときは、Raspberry Pi のCLIで[Ctrl]+[C]を押下後、[Y][Enter]を入力します。
再度、起動する場合は「./webui.sh」を実行し、再度、数時間ほど、待ってください。失礼しました。嘘ですm(_ _)m。すでにインストールが完了していた場合は、約10秒くらいで起動します。
また、設定変更などによって、必要なソフトウェアが生じた場合は、自動で追加のインストールが行われます。
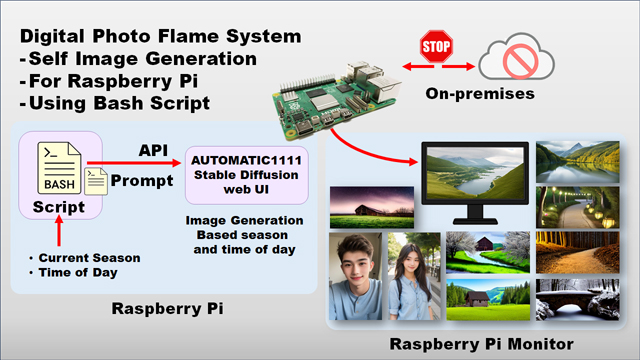
自動生成用Bashスクリプト
筆者が本稿用に作成した画像生成用のBashスクリプトについて説明します。

ダウンロード方法と実行方法
下記のコマンドでダウンロードできます。JSONから画像を抽出するのに jq コマンドを使用するので、インストールしてくださいます。
$ cd
$ git clone https://bokunimo.net/git/bash/
$ sudo apt install jq下記のコマンドで、Stable Diffusion web UI をバックグラウンドで起動し、筆者作成の Bashスクリプト を実行すると、画像生成を開始します。生成には約6分を要します(16 GBモデル時)。
$ cd ~/stable-diffusion-webui
$ ./webui.sh &
$ cd ~/bash/practical/stable_diffusion/
$ ./ex01_sd_basic.sh生成が完了したら、同じフォルダ内に「ex01_sd_basic.png」が作成されます。下図は生成した画像の一例です(低品質です)。

webui.shを停止するには、「fg⏎」を入力してから[Ctrl]+[C]を入力します。
画像生成用プロンプトを確認する
生成した画像をSrable Diffusion web UI の「PNG Info」にドラッグ&ドロップすると、生成プロンプトやモデル名などが表示されます。
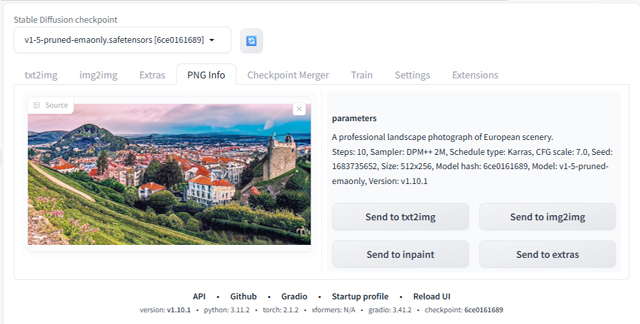
本例では、以下の情報が得られました。
A professional landscape photograph of European scenery.
Steps: 10, Sampler: DPM++ 2M, Schedule type: Karras, CFG scale: 7.0, Seed: 1683735652, Size: 512x256, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Version: v1.10.1この情報には、プロンプト「A professional landscape photograph of European scenery.」や、「Steps: 10」、「Model: v1-5-pruned-emaonly」などが含まれます。
プロンプトとStepsは、ex01_sd_basic.sh 内で設定しました。Stepsを大きくすると品質が上がります。ただし、数値に比例して生成時間も増えます。
sampler="DPM++ 2M"
scheduler="Karras"
width=512
height=256
steps=10 # 生成ステップ数(多いほど高品質)
cfg_scale=7
seed=-1
api_url="127.0.0.1:7860"
output_file="ex01_sd_basic.png"
# 画像生成用プロンプト
prompt="A professional landscape photograph of European scenery."画像生成APIの制御方法
本スクリプトでは、curlコマンドで Srable Diffusion web UI のAPIにアクセスします。
下記のように、JSON形式の生成用パラメータをHTTP POST送信し、受信データ・ファイルresponse.jsonに保存します。
curl -o response.json \
-X POST "http://"${api_url}"/sdapi/v1/txt2img" \
-H "Content-Type: application/json" \
-d "{
\"prompt\": \"$prompt\",
\"sampler_name\": \"$sampler\",
\"scheduler\": \"$scheduler\",
\"width\": $width,
\"height\": $height,
\"steps\": $steps,
\"cfg_scale\": $cfg_scale,
\"seed\": $seed
}"受信完了後、response.jsonに含まれる画像データをjqコマンドで抽出し、base64 –decode で復号化し、画像ファイルとして保存します。
image_base64=$(jq -r '.images[0]' response.json)
echo "$image_base64" | base64 --decode > "$output_file"生成画像の画質を改善する
画質を改善する方法はいくつかありますが、最も手軽なのは学習モデルの変更です。下図は、風景用モデルを使用した一例です。

上図は、architecture_Urban_SDlife_Chiasedamme_V6.0を使用して生成しました。使用するには、下記からモデルをダウンロードします。
風景用(architecture_Urban_SDlife_Chiasedamme_V6.0):
https://civitai.com/models/128280/architectureurbansdlifechiasedammev60
ダウンロードした拡張子safetensorのモデルは、モデル保存用のフォルダに保存してください。Web UI の「Stable Diffusion checkpoint」のプルダウンメニューから選択できるようになります。プルダウンメニューに表示されないときは、すぐ右にあるRefreshボタンを押してください。
モデル保存用フォルダ:
~/stable-diffusion-webui/models/Stable-diffusion/
architecture_Urban_SDlife_Chiasedamme_V6.0は、自然な風景だけでなく、人工的な建物の描写能力に長けたモデルです。風景全般の生成に役立つでしょう。

建物のディテールを高めたいときは、ex01_sd_basic.sh 内のsteps=15以上に変更します。概ね比例して、生成時間も増加します。steps=15で10分、steps=40で25分くらいです(RAM 16 GBの場合)。

ただし、steps数は大きければ良いというものでもありません。生成時間が長くだけでなるだけでなく、余計な画像処理を行うことがあります。

Promptを自動生成する
自動生成したプロンプトを、Srable Diffusion web UI に送信することで、画像を連続生成する方法について説明します。
風景画像用プロンプトの自動生成
ex02_sd_scenery.sh は、風景を示すプロンプトと、現在の季節、現在時刻を組み合わせてプロンプトを自動生成し、Srable Diffusion web UI に渡すサンプル・プログラムです。
webui.sh を実行した状態で、下記を実行してください。
$ cd ~/bash/practical/stable_diffusion/
$ ./ex02_sd_scenery.sh 現在の季節や時刻に応じた風景画像を連続で自動生成します。停止は、[Ctrl]+[C]です。

下記はプロンプト生成部です。変数sceneries、month_unit、hour_unit内に、それぞれ風景、月、時間を代入しておき、プロンプトに組み込みます。
prompt=""
prompt+="A professional landscape photograph of scenery, "
prompt+="realistic DSLR quality, suitable for a calendar. "
prompt+="(A European "${sceneries[$(( $RANDOM % sceneries_num ))]}" "
prompt+=${month_unit}" "${hour_unit}"), "
prompt+="balanced cinematic composition with depth of field, natural colors, "
prompt+="wide-angle view, high resolution, realistic photo style. "学習モデルの変更で画質向上する
もちろん、学習モデルの変更で画質の向上も可能です。モデルをダウンロード後、ブラウザのWeb UIで、モデルを変更してからスクリプト ex02_sd_scenery.sh を実行してみてください。
下図は、 architecture_Urban_SDlife_Chiasedamme_V6.0 に変更した場合の一例です。

また、人物用の japaneseStyleRealistic_v20 に変更した場合、人物だけでなく、風景の生成能力も向上します。

人物画像の生成
次は、人物画像です。標準モデルv1-5-pruned-emaonlyで生成した画像の一例を下図に示します。一部の画像に、自然さの不足を感じる部分があると思います。

※ご注意:
本稿の「人物」とはAIによる生成画像を示します。実在する人物を示すものではありません。また、上図の一例はAI生成能力を比較するためのものです。実在する人物に対する偏見や差別を意図したものではありません。「自然な人物」とは、あくまで平均的な人物像との比較表現であり、個性を否定する意図は一切ありません。もし、特定の人物画像や表現に対して不快な印象を持たれ、引き続き当サイトをご利用いただく必要がある場合は、匿名にて連絡ください(ゲストブック ※匿名と明記ください)。
人物用の学習モデルで画質を向上する
モデルを変更することで、下図のような自然な人物の画像(個性に傾きが少ない画像)を生成できるようになります。

使用スクリプト = ex03_sd_human.sh
学習モデル japaneseStyleRealistic_v20 は、下記からダウンロードし、フォルダ models → Stable-diffusion 内に保存します。
風景+人物用(japaneseStyleRealistic_v20):
https://civitai.com/models/56287/japanese-style-realistic-jsr
このモデルの特長は、自然な日本人女性の画像生成です。このため、男性を指示しても女性が表示されることがあります。

使用スクリプト = ex03_sd_human.sh
日本人男性の画像を生成したい場合は、 beautifulRealistic_v7 が良いでしょう。
人物用(beautifulRealistic_v7):
https://civitai.com/models/25494/beautiful-realistic-asians

西洋人はどちらのモデルであっても生成可能です。やや東洋系の雰囲気が出ますが、むしろ日本人にとっては自然な西洋人に見えるでしょう(筆者の主観)。

人物画像用プロンプトの自動生成
プロンプトを生成するスクリプトは、ex03_sd_human.sh です。webui.sh を実行した状態で、下記を実行してください。
$ cd ~/bash/practical/stable_diffusion/
$ ./ex03_sd_human.sh 生成には約22分の時間を要します(RAM 16GBモデル)。メモリーの使用量が8GBを超えることがあります。RAM 8GBモデルの場合は、メモリーの節約や生成解像度を下げる等の対策が必要です。
[PR]書籍 Linux コマンド & シェルスクリプト入門
PRです。Linuxコマンドや Bashスクリプトの入門書を書かせていただきました。画像生成AIの応用記事はありませんが、少ない学習量でLinuxコマンドやBashスクリプトを使いこなすことを目標にした一冊です。興味がありましたら、下記から目次をご覧いただければと思います。
Raspberry Pi 5 4GB RAM モデルでの実行結果
本稿で紹介した画像生成には、5GB 以上のRAMを使用します。このため、RAM 4GB モデルの場合は RAM圧縮 とSDカードやSSDへのスワップが必須です。また、生成時間も長くなります。
解像度を384×256に下げる
下図は、RAM容量 4GB のモデルでの実行結果の一例です。画像生成の仕上げ処理時のメモリ超過対策のため、解像度を384×256にしました。

RAM容量4GB時の生成時間は60倍
Lite版OSを使用し、Stable Diffusion のオプションでメモリー節約を設定し、RAM圧縮を設定し、swappinessを10%まで下げたとしても、画像生成中はスワップが常時発生します。
下記は Raspberry Pi 5 4GB RAM モデルで画像生成した時の時間の一例です。16 GB モデルの約60倍の時間がかかりました。
| 生成回数 | 生成時間 | 16GB 比較 |
| 1回目 | 6時間 53分 | 83 倍 |
| 2回目 | 5時間 22分 | 64 倍 |
| 3回目 | 4時間 31分 | 54 倍 |
| 4回目 | 5時間 04分 | 61 倍 |
動作の様子はLEDで確認する
4GB RAMモデルでの画像生成中は、コマンドの実行も難しくなります。そこで、LEDの点滅具合で負荷を確認します。

画像生成中は、0.数秒~数秒の間隔でLEDが瞬時的に点灯して、すぐに消灯するような動作を繰り返します。
消灯しっぱなしの場合や、消灯している秒数が長い場合は、画像生成が進んでいないことを示しています。この場合、丸1日、かけても終了しません。さらに解像度を下げる、高速なマイクロSDカードに変更するなど、スワップを低減してください。
なお、SDカードへの書き込み頻度が高いので、SDカードの書き換え寿命への耐性も必要です。ドライブレコーダー用の高耐久SDカードや、SSDなど、書き換え耐性の高いドライブの使用を推奨します。
SSDで生成速度を20倍速にする
RAM 4GB モデルで時間を要する原因は、マイクロSDカードへの読み書き時間です。そこで、スワップ先をUSB接続の SSD にすると、改善できます。

本稿執筆後、RAM 4GB モデルで画像生成するための設定やSSDドライブの選定方法などを、別ページに執筆しました。
Raspberry Pi の RAM 4GBモデルをお持ちの方は、ぜひ下記のブログ・ページを参照してください。

注意事項
画像生成AIは、実在する写真のような画像を生成することができます。このため、利用には社会のルールや規則を守ることはもちろんのこと、未だ規則化されていない部分の配慮も必要です。
とくに、偶発的に倫理性を損なう画像が生成される懸念や、偶発的に実在する人物に似た画像が生成される懸念、性別や容姿などに偏見や差別を含んでしまう懸念などがあります。筆者が作成したスクリプトにおいても、そういった画像が生成される場合がありますので、生成した画像の取り扱いには十分に注意してください。
また、自分自身の倫理観が社会とずれている部分や、時代とともに変わっている部分、配慮不足といったことも発生し得ます。
本稿の執筆時には、これらについて注意しながら作成しましたが、そのような点が残存する可能性がある点に、ご理解をいただけるよう、お願いいたします。もちろん、ご指摘いただければ、本稿の趣旨を損なわない範囲で修正いたします。
by bokunimo.net
「Raspberry Pi 上から Bashスクリプトで Stable Diffusion を制御する」への2件の返信
[…] RAM 16GB(or 8GB)単体https://bokunimo.net/blog/raspberry-pi/6065 […]
[…] Raspberry Pi 上から Bashスクリプトで Stable Diffusion を制御する […]